
有部分私有项目是不方便使用公网API或AI IDE来实时推理代码辅助生成的,之前一直使用ollama配合continue,模型Qwen-Coder-14B, 但continue现在商业感越来越浓,本地模型的部署配置也越藏越深。
换Tabby试试。
brew install tabbyml/tabby/tabby下载模型并运行
tabby serve --device metal --model Qwen2.5-Coder-14B
打开web后台进行配置,完成后可以查看模型运行状态
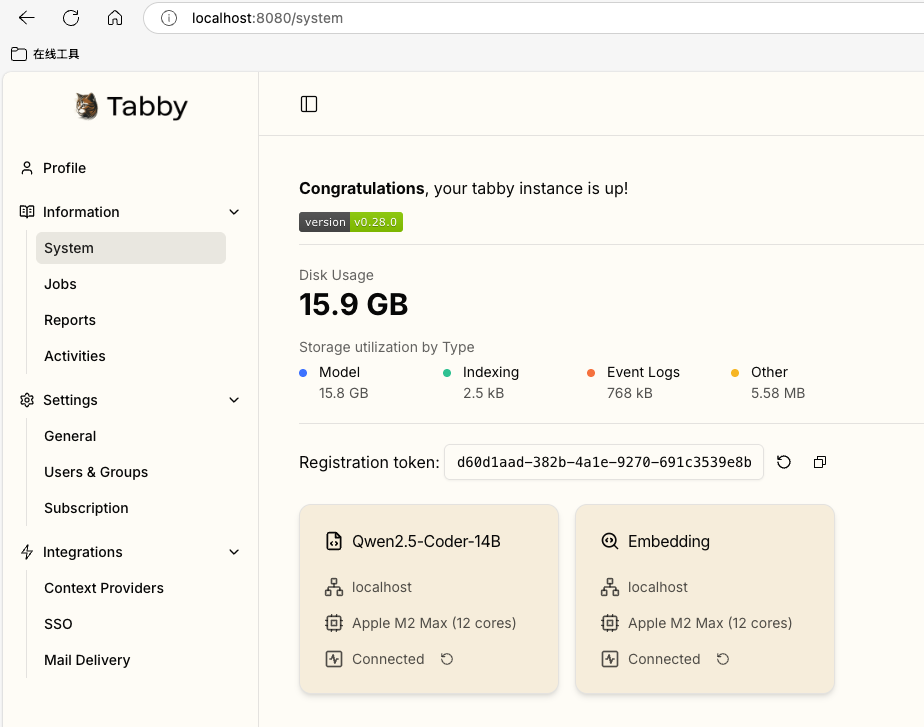
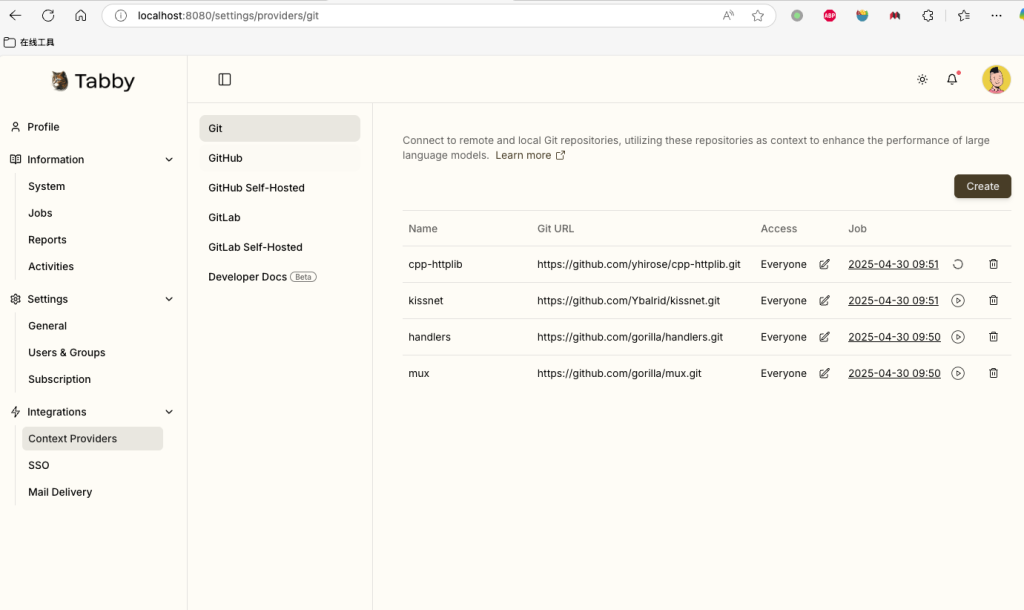
重点来了,tabby还能自动部署 上下文提供者来增强大型语言模型的性能。
现在回到VSCode,安装扩展 tabby
生成速度和质量还不错,意图理解也准确。
配置好之后,将tabby以服务自启动, 先修改配置 code .tabby/config.toml
[model.completion.local]
model_id = "Qwen2.5-Coder-14B"然后再运行
brew services start tabby与ollama的区别:
ollama 拉取的模型,默认为Q4_K_M量化,模型大小9G
tabby 拉取的是Q8_0量化,模型大小15G
M2 Max 32G统一内存下都能流畅运行。
原创文章,转载请注明: 转载自贝壳博客
本文链接地址: 本地部署自托管的AI编码助手