查找当前目录下所有flv文件,复制音视频,转换为mp4格式并修改后缀名
for f in *.flv; do ffmpeg -i $f -c copy ${f:0:0-4}.mp4; done查找当前目录下所有mp4文件,使用aac, x265重新编码,保存为mkv格式并修改后缀名
for f in *.mp4; do ffmpeg -i $f -c:a aac -c:v libx265 ${f:0:0-4}.mkv; done
查找当前目录下所有flv文件,复制音视频,转换为mp4格式并修改后缀名
for f in *.flv; do ffmpeg -i $f -c copy ${f:0:0-4}.mp4; done查找当前目录下所有mp4文件,使用aac, x265重新编码,保存为mkv格式并修改后缀名
for f in *.mp4; do ffmpeg -i $f -c:a aac -c:v libx265 ${f:0:0-4}.mkv; doneSIMD全称Single Instruction Multiple Data,单指令多数据流,能够复制多个操作数,并把它们打包在大型寄存器的一组指令集。
以加法指令为例,单指令单数据(SISD)的CPU对加法指令译码后,执行部件先访问内存,取得第一个操作数;之后再一次访问内存,取得第二个操作数;随后才能进行求和运算。而在SIMD型的CPU中,指令译码后几个执行部件同时访问内存,一次性获得所有操作数进行运算。这个特点使SIMD特别适合于多媒体应用等数据密集型运算。
在微处理器中,单指令流多数据流技术则是一个控制器控制多个平行的处理微元,如X86中的SSE,AVX,Arm中的Neon,现在叫asimd。
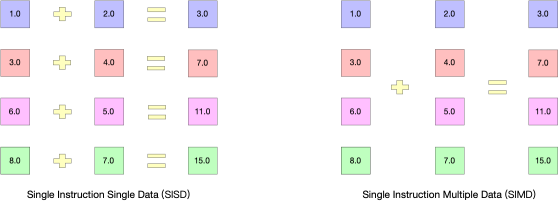
在js运行环境中,目前还没有完美的线程方案来利用多核解码,那么我们可以优化至少让单核进行并行运算。这是chrome91和firefox89正式带来的WebAssembly SIMD技术。

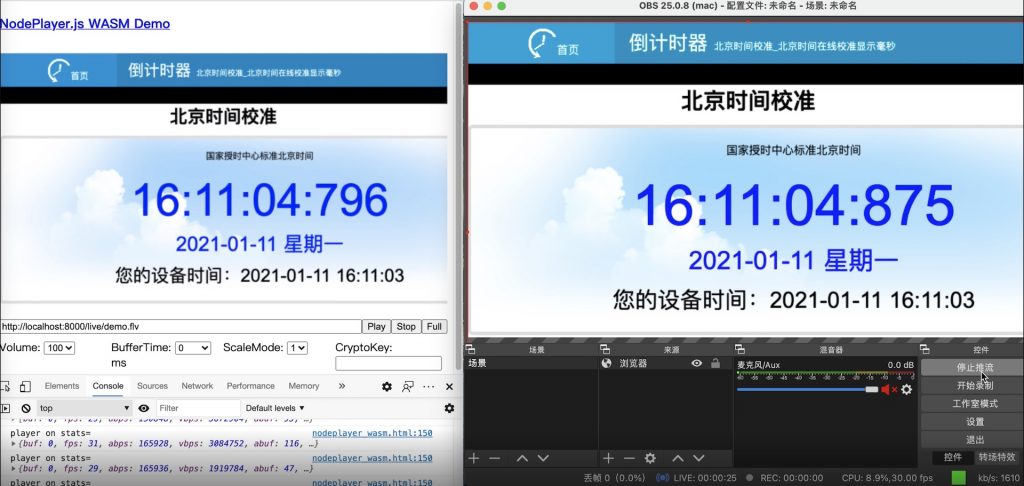
NodePlayer.js 更新v0.10.1版,利用这项技术,在高分辨率解码环境下,带来比SISD性能提升1倍以上!尤其是在高分辨率,HEVC解码下。
测试对比:
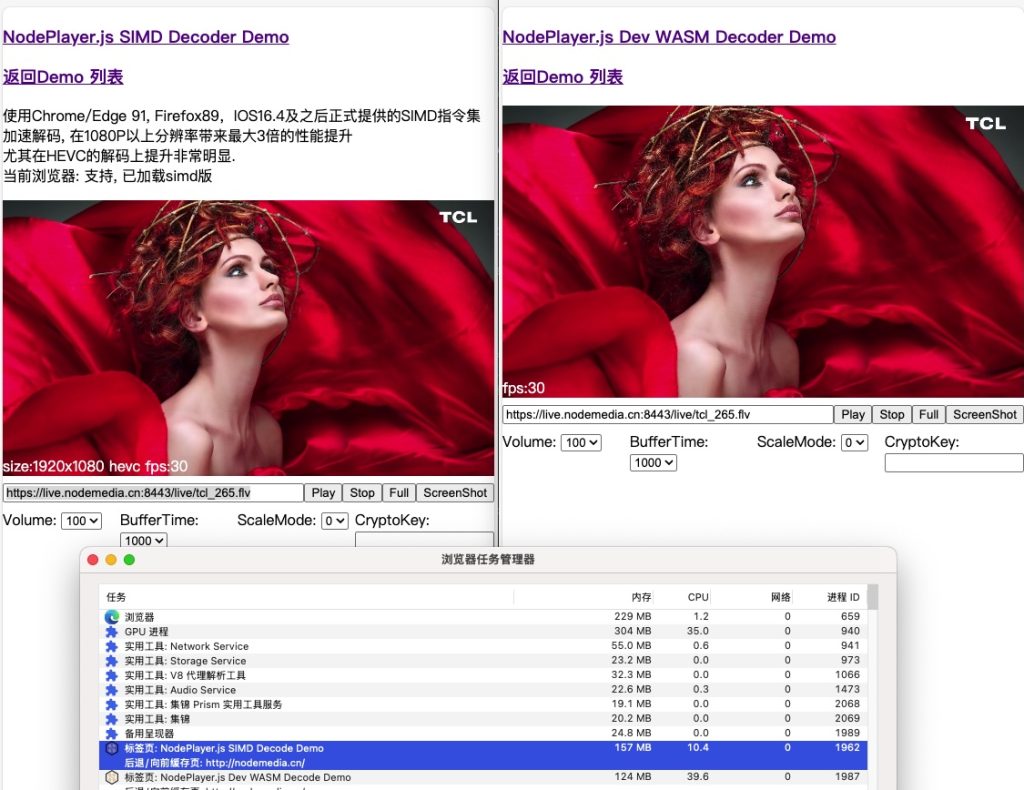
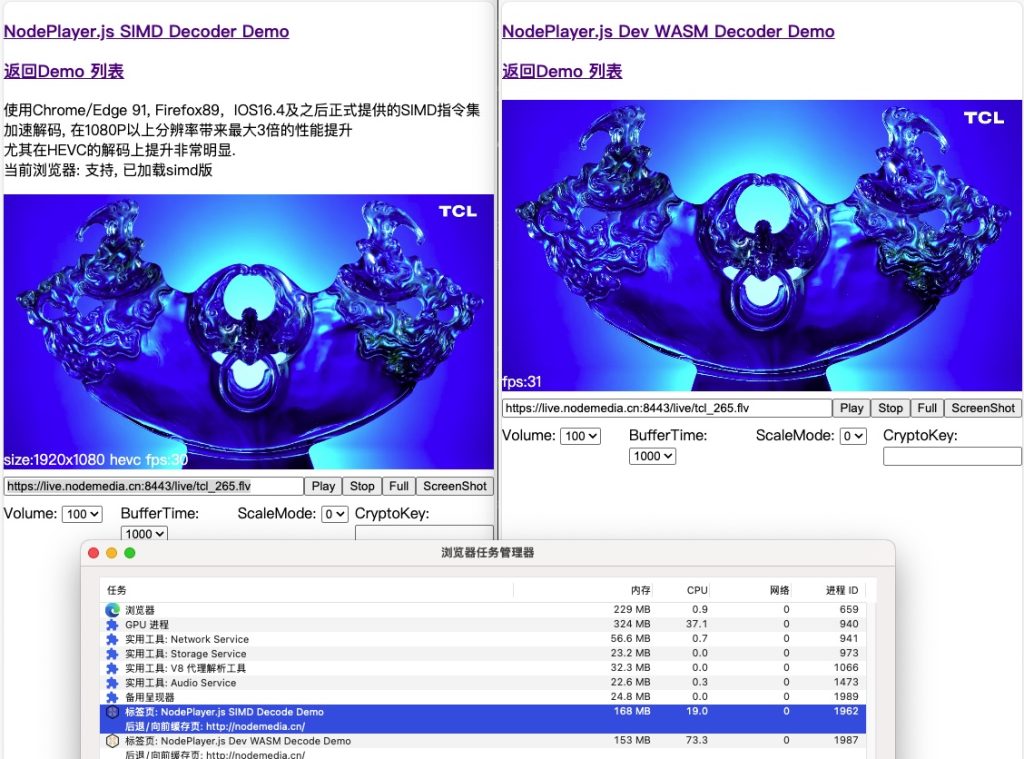


可以看到,SIMD版解码在大多数场景下,CPU占用率只有WASM的1/3 。
wasm 版在线demo:http://demo.nodemedia.cn/uploads/nodeplayer_wasm.html
simd 版在线demo:http://demo.nodemedia.cn/uploads/simd/index.html
NodePlayer.js 文档:https://www.nodemedia.cn/doc/web/#/1?page_id=1
目前JETPACK SDK镜像是4.5.1版
Jetson Nano 4G 内存版,下载链接:https://developer.nvidia.com/jetson-nano-sd-card-image
Jetson Nano 2G内存版,下载链接:https://developer.nvidia.com/jetson-nano-2gb-sd-card-image
系统镜像6G,默认安装ubuntu desktop等桌面软件,体积非常大,如果项目开发完成,想要将工程文件直接集成到镜像里,进行批量烧录,那么可以通过自制镜像的方式来实现。以下针对Nano版整理的制作方法。
一款用于调试RTMP、KMP、HTTP-FLV流时间戳的小工具。
通过这个工具,可以直观的打印出每一帧音视频的信息,包括时间戳,包大小。
一个流畅的直播视频应该符合以下三个状态
一、每一帧数据匀速打印,无停顿。如果停止打印说明无数据返回,有两种情况:第一种是推流端网络阻塞,第二种是播放端网络阻塞。这个比较好判断,使用两台机器测试,如果停顿在同一个时间点,则是推流端阻塞;分别在不同的时间点停顿,则是播流端阻塞。还需要对服务端的上下行带宽进行评估是否已达上限。
二、音视频帧交替打印
以44100采样的aac举例,aac编码一个包需要1024个采样。这时,一帧的时长就是 1000/44100*1024 约等于23.219954648526077毫秒。
如果视频是30fps,则一帧的时长是1000/30 约等于33.3333毫秒。
这时候音视频一般会是AVAVAAV的排列。
如果出现连续上10个以上同类型包,则要考虑是否是编码器音视频编码不同步。
三、时间戳增长与时钟增长频率一致
RTMP,KMP、HTTP-FLV的时间基是1/1000秒,因此通过观察单位时间内时间戳的增长数应该与时钟一致。如果不一致,常见于从其它协议转RTMP时,时间单位换算错误。如RTSP: H264/90000 PCMA/8000
NodeMediaClient-WinPlugin 用于Windows系统下,ie浏览器和360浏览器极速模式下的直播插件。最新的EDGE,Chrome,Firefox浏览器均移除了NPAPI插件的支持。只有国内部分浏览器如:360(安全、极速)浏览器,搜狗浏览器保留了NPAPI的支持。由于使用率较低,NodeMediaClient-WinPlugin曾一度停止开发。2020年12月flash停止支持并强制从windows系统下移除,导致不少项目无法正常使用。NodeMediaClient-WinPlugin在RTMP直播播放场景下完全可以替代flash,并且拥有更好的性能与播放体验。
本次更新重构了播放核心,使用了NodePlayer.js的延迟消除算法,延迟更低、体验更好。并且支持主流的Intel\Nvidia\AMD显卡硬件加速。4k60帧也流畅播放无压力。
ffmpeg -re -i bbb_sunflower_2160p_60fps_normal.mp4 -c copy -f flv rtmp://192.168.0.2/live/s
https://cdn.nodemedia.cn/NodeMediaClient-WinPlugin/0.5.0/NodeMediaClient_v0.5.0.msi
https://cdn.nodemedia.cn/NodeMediaClient-WinPlugin/0.2.9/NodeMediaClient_v0.2.9.0-trial.zip
https://down.360safe.com/cse/360cse_13.0.2206.0.exe
YUV420
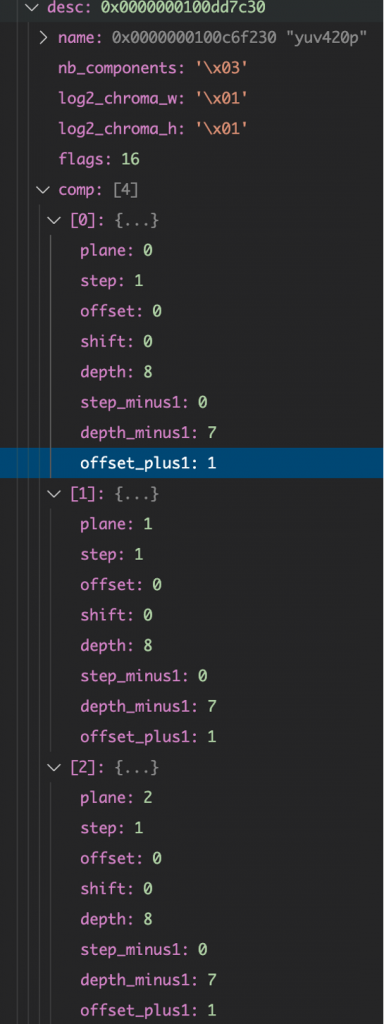
NV12:
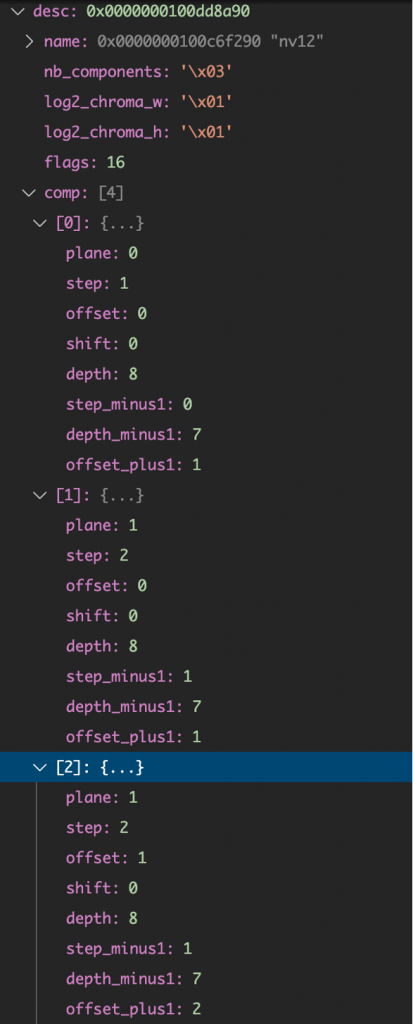
可以看出,就图像格式描述而言,它们都是3组数据,不同在于:
YUV420P的
U分量是plane:1、step:1、offset:0
V分量是plane:2,step:1、offset:0
NV12的
U分量plane:1、step:2、offset:0
V分量plane:1、step:2、offset:1
要挑战100毫秒级的p2s2p型直播,我们首先要了解延迟到底是怎么产生的?
1.推流端p采集原始画面,交给编码器编码,根据编码复杂度,编码器缓存,在这里就产生了延迟。(可控参数较多,影响较大)
2.推流端p编码后推送到s服务端,网络传输产生延迟。(以现在的网络环境,影响小)
3.服务端s接收地视频后进行协议转换,不同的服务实现可能会在这里造成一点延迟。(以现在的服务端性能,影响小)
4.播放端p播放,网络传输产生延迟。(以现在的网络环境,影响小)
5.播放端p解码渲染、缓冲队列产生延迟。(音视频同步、数据缓冲、延迟消除算法复杂,影响很大)
由此可以看出,要实现低延迟,重点优化推播两端是效果最明显的。
测试环境:
OBS设置x264软编码,CBR,2500kbps, veryfast,zerolatency,baseline,1s gop,0 buffer,视频尺寸1920×1080@30
推流到本机NMS-v3.7.3 (忽略网络对延迟的影响,测试极限条件)
NodePlayer.js-v0.5.56, bufferTime设置为0
实测,最低延迟79毫秒!
AudioDecoder, VideoDecoder, and VideoEncoder may produce outputs or errors after calling reset().
有被爽到
最近实现了NMSv3接收GB28181设备注册,下发指令主动通知摄像头以RTP推流到NMS,转为RTMP, KMP, FLV播放。
NMSv3不是完整的GB28181实现,我将SIP信令与RTP流媒体服务器合二为一,仅作为实时视频取流的用途。
当我准备实现设备注册,密码验证时,找到一篇博文:https://blog.csdn.net/hiccupzhu/article/details/39696981
其中讲到的算法是:
HA1=MD5(username:realm:passwd) #username和realm在字段“Authorization”中可以找到,passwd这个是由客户端和服务器协商得到的,一般情况下UAC端存一个UAS也知道的密码就行了
HA2=MD5(Method:Uri) #Method一般有INVITE, ACK, OPTIONS, BYE, CANCEL, REGISTER;Uri可以在字段“Authorization”找到
response = MD5(HA1:nonce:HA2)
对比REGISTER中的response与计算的response,相同则验证通过。
但我却验证错误,仔细阅读了exosip这部分的代码后,终于找出差异:https://github.com/aurelihein/exosip/blob/master/src/jauth.c#L144
当设备第一次发送REGISTER,NMS回复401, 并附带
WWW-Authenticate: Digest realm="3402000000", nonce="a321cfdd39ff6233"还有一种回复是
WWW-Authenticate: Digest realm="3402000000", qop="auth", nonce="a321cfdd39ff6233"原来这个qop的设置与否,决定了验证算法的差异。
当不设置qop时,确实是使用上面的那种算法进行验证。而设置为”auth”后,则使用下面的这个算法:
HA1=MD5(username:realm:passwd) #username和realm在字段“Authorization”中可以找到,passwd这个是由客户端和服务器协商得到的,一般情况下UAC端存一个UAS也知道的密码就行了
HA2=MD5(Method:Uri) #Method一般有INVITE, ACK, OPTIONS, BYE, CANCEL, REGISTER;Uri可以在字段“Authorization”找到
response = MD5(HA1:nonce:nc:cnonce:qop:HA2)
可以看出,HA1、HA2是相同的,区别在于resopnse有差别。开发时需要注意这点,如果想使用简单的验证算法,回复401时,不要传qop=”auth”参数。
另外还有一种qop=”auth-int”的算法,这里由于决定权在服务端,所以不做详细研究。如果做向上级级联,则要根据上级401的参数来响应。