简介
前面有介绍如何在白鹭引擎中使用NodePlayer.js,今天做了Laya引擎的集成尝试,方法如下。
环境
NodePlayer.js wasm版 v0.5.42
LayaAir 2.8.0beta2
LayaAir IDE 2.8.0beta2
创建项目
新建一个2D示例项目,编程语言使用TypeScript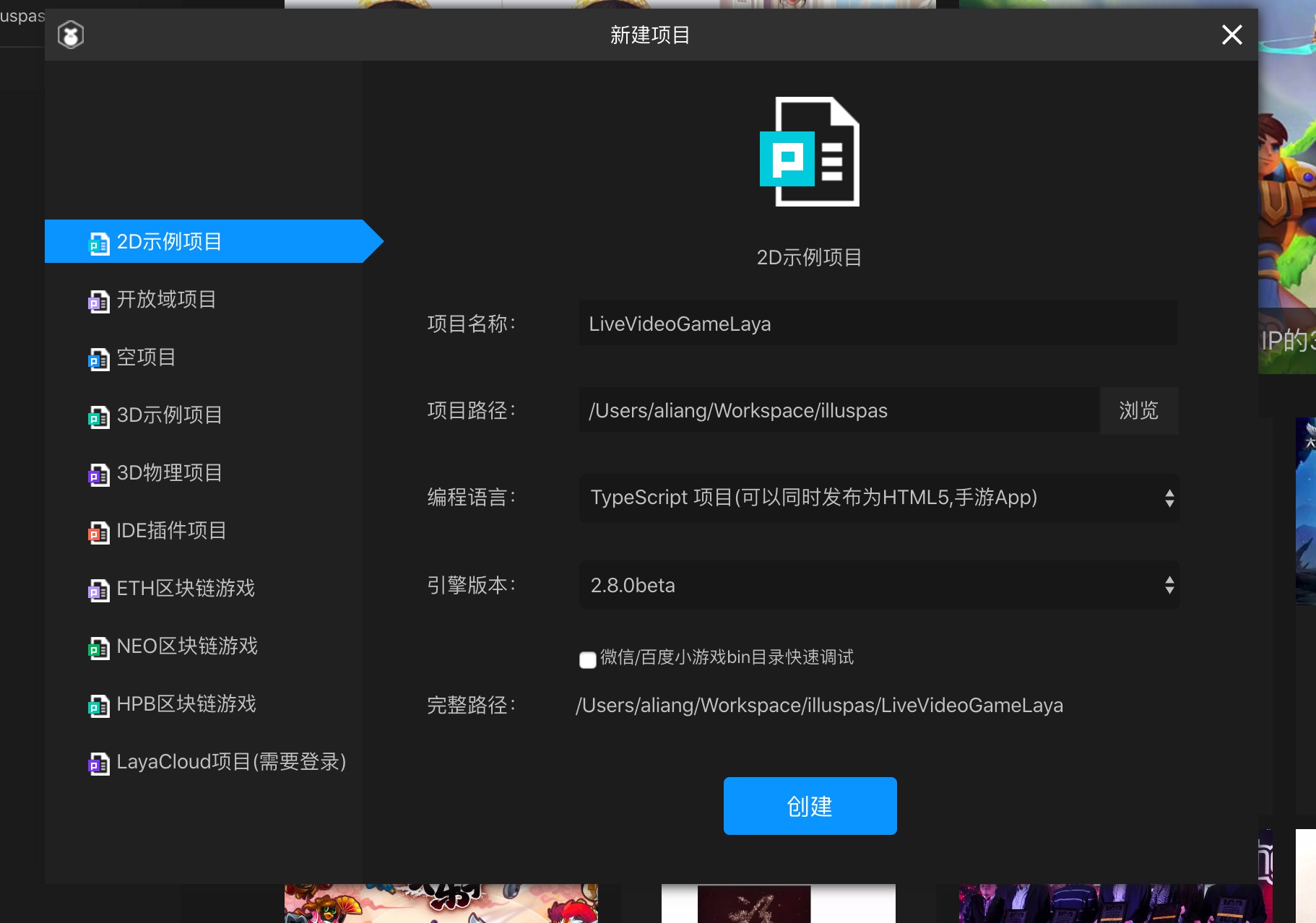

前面有介绍如何在白鹭引擎中使用NodePlayer.js,今天做了Laya引擎的集成尝试,方法如下。
NodePlayer.js wasm版 v0.5.42
LayaAir 2.8.0beta2
LayaAir IDE 2.8.0beta2
新建一个2D示例项目,编程语言使用TypeScript
实时视频+游戏操作是非常不错的娱乐体验方式,结合物联网设备可以开发诸如:远程抓娃娃、远程打气球、打野兔、射箭等项目。
NodePlayer.js-wasm版可以非常方便的集成到最新的白鹭引擎(v5.3以上)中使用,以下是我们总结的一个集成方法。
试用开发包请下载:https://cdn.nodemedia.cn/NodePlayer/0.5.39-wasm/NodePlayer_v0.5.39-wasm_trial.zip
授权用户请准备好wasm版
detectnet 可以直接打开rtsp网络摄像头作为输入源,进行实时视频分析,在监控领域有非常大的应用。
尝试了下打开rtmp流,没有成功,返回说不支持。
从日志输出来看是使用GStreamer。
[gstreamer] gstDecoder -- unsupported protocol (rtmp)
[gstreamer] supported protocols are:
[gstreamer] * file://
[gstreamer] * rtp://
[gstreamer] * rtsp://
[gstreamer] gstDecoder -- failed to build pipeline string
[gstreamer] gstDecoder -- failed to create decoder for rtmp://192.168.0.2/live/bbb
detectnet: failed to create input stream
如果是GStreamer,那当然应该支持rtmp才对。打开并修改源码
jetson-inference/utils/codec/gstDecoder.cpp
NVIDIA TensorRT™是一个高性能深度学习推理平台。它包括深度学习推理优化器和运行时,可为深度学习推理应用程序提供低延迟和高吞吐量。在推理期间,基于TensorRT的应用程序比仅CPU平台的执行速度快40倍。使用TensorRT,您可以优化在所有主要框架中培训的神经网络模型,以高精度校准低精度,最后部署到超大规模数据中心,嵌入式或汽车产品平台。
TensorRT构建于NVIDIA的并行编程模型CUDA之上,使您能够利用CUDA-X AI中的库,开发工具和技术,为人工智能,自动机器,高性能计算和图形优化所有深度学习框架的推理。
TensorRT为深度学习推理应用的生产部署提供INT8和FP16优化,例如视频流,语音识别,推荐和自然语言处理。降低精度推断可显着减少应用程序延迟,这是许多实时服务,自动和嵌入式应用程序的要求。

您可以将训练有素的模型从每个深度学习框架导入TensorRT。应用优化后,TensorRT选择特定于平台的内核,以最大限度地提高数据中心,Jetson嵌入式平台和NVIDIA DRIVE自动驾驶平台中Tesla GPU的性能。
为了在数据中心生产中使用AI模型,TensorRT推理服务器是一种容器化微服务,可最大化GPU利用率,并在节点上同时运行来自不同框架的多个模型。它利用Docker和Kubernetes无缝集成到DevOps架构中。
使用TensorRT,开发人员可以专注于创建新颖的AI驱动的应用程序,而不是用于推理部署的性能调整。
继续阅读“Jetson 把玩记 二、TensorRT 环境搭建”最近得空,搞了一块Jetson Nano玩玩。

NVIDIA 在2019年NVIDIA GPU技术大会(GTC)上发布了Jetson Nano开发套件,这是一款售价99美元的计算机,现在可供嵌入式设计人员,研究人员和DIY制造商使用,在紧凑,易用的平台上提供现代AI的强大功能。完整的软件可编程性。Jetson Nano采用四核64位ARM CPU和128核集成NVIDIA GPU,可提供472 GFLOPS的计算性能。它还包括4GB LPDDR4存储器,采用高效,低功耗封装,具有5W / 10W功率模式和5V DC输入,如图1所示。
新发布的JetPack 4.2 SDK 为基于Ubuntu 18.04的Jetson Nano提供了完整的桌面Linux环境,具有加速图形,支持NVIDIA CUDA Toolkit 10.0,以及cuDNN 7.3和TensorRT等库。该SDK还包括本机安装流行的功能开源机器学习(ML)框架,如TensorFlow,PyTorch,Caffe,Keras和MXNet,以及计算机视觉和机器人开发的框架,如OpenCV和ROS。
完全兼容这些框架和NVIDIA领先的AI平台,可以比以往更轻松地将基于AI的推理工作负载部署到Jetson。Jetson Nano为各种复杂的深度神经网络(DNN)模型提供实时计算机视觉和推理。这些功能支持多传感器自主机器人,具有智能边缘分析的物联网设备和先进的AI系统。甚至转移学习也可以使用ML框架在Jetson Nano上本地重新训练网络。
话不多说直接开干。
继续阅读“Jetson 把玩记 一、初次运行”clang在Windows下可以很方便的引用msys2的开发环境。
vscode在linux,mac下安装cmake tools插件也差不多能达到相同功能。
但该插件在windows下,想要引用msys2还是遇到问题了。
ctrl+p,>CMake:Edit User-Local CMake Kits 需要如下设置:
{
"name": "GCC 10.1.0",
"compilers": {
"C": "D:\\msys64\\mingw32\\bin\\gcc.exe",
"CXX": "D:\\msys64\\mingw32\\bin\\g++.exe"
},
"environmentVariables": {
"PATH": "${env:PATH};d:\\msys64\\mingw32\\bin"
}
},添加environmentVariables是关键
NodePlayer.js设计之初只是为了播放http-flv协议,但经常有客户想要知道能否播放RTMP协议,甚至RTSP协议,以往我们的回答都是不能。web浏览器没有开放TCP/UDP协议,当然无法实现RTMP、RTSP播放了。
但从 NodePlayer.js-v0.7版本开始,我们已经实现RTMP协议的播放了!
当然,不是TCP协议的RTMP, 没有这个基础条件。我们实现的方式,是通过WebSocket协议来和一个 websocket 2 tcp 服务交换协议,最终和RTMP服务器建立连接。
本播放器无需flash插件,和video.js等播放RTMP的方式完全不同。
如果您正在构建新的直播项目,其实无需使用本技术。如今的流媒体服务端或者云服务,基本上都支持HTTP-FLV甚至WebSocket-FLV。
本功能是为以往使用Flash-Media-Server, Adobe-Media-Server, Nginx-RTMP, Red5,Wowza等服务端构建项目的用户,在不改变现有架构的条件下,无痛迁移到HTML5播放器。
实际上无需过多要求,只需要一个 websocket to tcp的桥接服务。
这里,我们以一个非常轻量级,且开放源代码的ws-tcp-relay项目为例。
项目地址:https://github.com/isobit/ws-tcp-relay
进入https://github.com/isobit/ws-tcp-relay/releases ,根据服务端系统选择并下载应用程序
下载后,linux系统下添加可执行权限,然后执行
./ws-tcp-relay -b -p 8080 192.168.0.3:1935参数说明:
-b 使用binary格式传输
-p 绑定本机8080端口监听websocket连接
192.168.0.3:1935 需要桥接的远端或者本地 rtmp服务,本机可以填 127.0.0.1:1935
使用NodePlayer.js-v0.7版播放器,播放地址
rtmp://运行ws-tcp-relay服务的ip:8080/live/stream即可
如果要去掉端口号, ws-tcp-relay改为监听80端口,但可能会和webserver冲突
这里不清楚nginx反向代理是否有能力转websocket to tcp,如果能的话那就更方便。
http://www.nodemedia.cn/uploads/nodeplayer_rtmp.html
使用前请先运行ws-tcp-relay服务
理论上,也是可以的,敬请期待。
这种情况不管是本地运行WordPress还是阿里云ecs上,安装更新、插件、主题,都会出现。估计是woredpress的cdn对国内ip做了限流。
更新失败:下载失败。 Too Many Requests
我解决的办法是给添加一个http proxy来解决,注意一定要是http_proxy,socks5请加一层代理转换,比如privoxy。
非常简单,打开wp-config.php,在合适的位置添加:
define('WP_PROXY_HOST', '127.0.0.1');
define('WP_PROXY_PORT', '8118');
define('WP_PROXY_BYPASS_HOSTS', 'localhost');
首先我们知道,Rtmp是一种客户端到服务端的技术,Peer to Server。WebRTC是一种客户端到客户端的技术,Peer to Peer。
Rtmp通过一个TCP连接,向服务端发送或接收连接信息,媒体数据。
WebRTC先使用ICE技术连接STUN/TURN,得到自己的连接信息。再绑定音视频设备获取媒体信息,拼装为SDP信令。两个客户端通过任意方式交换信令,建立客户端直接的连接,再使用RTP发送和接收媒体数据。
如果一个服务端实现了WebRTC客户端的能力,那么它也可以被认为是一个Peer,与用户浏览器的WebRTC客户端创建连接,获得客户端推送过来的媒体数据,就完成了Peer to Server的转换。
继续阅读“WebRTC 研究系列 二、打通webrtc与rtmp”xcode 11.3.1 已安装,执行
sudo gem install cocoapods
出现错误
RROR: Error installing cocoapods:
ERROR: Failed to build gem native extension.
current directory: /Library/Ruby/Gems/2.3.0/gems/ffi-1.12.2/ext/ffi_c
/System/Library/Frameworks/Ruby.framework/Versions/2.3/usr/bin/ruby -r ./siteconf20200319-1090-1u4hxao.rb extconf.rb
mkmf.rb can't find header files for ruby at /System/Library/Frameworks/Ruby.framework/Versions/2.3/usr/lib/ruby/include/ruby.h
extconf failed, exit code 1
执行下面的命令,安装后, 问题解决
open /Library/Developer/CommandLineTools/Packages/macOS_SDK_headers_for_macOS_10.14.pkg